








文章责编:wuchong
看了本文的网友还看了学历| 高考 中考 考研 自考 成考 外语| 四六级 职称英语 商务英语 公共英语 资格| 公务员 报关员 银行 证券 司法 导游 教师 计算机| 等考 软考
工程|一建 二建 造价师 监理师 咨询师 安全师 结构师 估价师 造价员 会计| 会计证 会计职称 注会 经济师 税务师 医学| 卫生资格 医师 药师 [更多]
| 第 1 页:试题 |
| 第 6 页:参考答案 |
一、选择题
(1)B【解析】算法的控制结构给出了算法的基本框架,它不仅决定了算法中各操作的执行顺序,而且也直接反映了算法的设计是否符合结构化原则。一个算法一般都可以用顺序、循环、选择三种基本控制结构组合而成。本题答案为B。
(2)C【解析】链式存储结构克服了顺序存储结构的缺点:它的节点空间可以动态申请和释放;它的数据元素的逻辑次序靠节点的指针来指示,不需要移动数据元素。故链式存储结构下的线性表便于插入和删除操作。本题答案为C。
(3)C【解析】快速排序的基本思想是,通过一趟排序将待排序记录分割成独立的两部分,其中一部分记录的关键字均比另一部分记录的关键字小,再分别对这两部分记录继续进行排序,以达到整个序列有序;插入排序的基本操作是指将无、序序列中的各元素依次插入到已经有序的线性表中,从而得到一个新的序列;选择排序的基本思想是:扫描整个线性表,从中选出最小的元素,将它交换到表的最前面(这是它应有的位置),然后对剩下的子表采用同样的方法,直到表空为止;归并排序是将两个或两个以上的有序表组合成一个新的有序表。本题答案为C。
(4)A【解析】软件工程包括3个要素,即方法、工具和过程。本题答案为A。
(5)B【解析】结构化分析的常用工具有数据流图、数据字典、判定树和判定表。而流程网是常见的过程设计工具中的图形设计。本题答案为B。
(6)A【解析】软件的白盒测试方法是把测试对象看做一个打开的盒子,它允许测试人员利用程序内部的逻辑结构及有关信息,设计或选择测试用例,对程序所有逻辑路径进行测试。本题答案为A。
(7)C【解析】在文件系统中,相互独立的记录其内部结构的最简单形式是等长、同格式的记录的集合,易造成存储空间大量浪费,不方便使用。而在数据库系统中,数据是结构
化的,这种结构化要求在描述数据时不仅描述数据本身,还要描述数据间的关系,这正是通过采用特定的数据模型来实现的。本题答案为C。
(8)D【解析】数据模型所描述的内容有3个部分,它们是数据结构、数据操作和数据约束。其中,数据模型中的数据结构主要描述数据的类型、内容、性质,以及数据库的联系等;数据操作主要是描述在相应数据结构上的操作类型与操作方式。本题答案为D。
(9)A【解析】层次模型是最早发展出来的数据库模型。它的基本结构是树形结构,这种结构方式在现实世界中很普遍,如家族结构、行政组织机构,它们自顶向下、层次分明。关系模型是用二维表的形式表示实体和实体间联系的数据模型。关系模型的特点如下:关系模型与非关系模型不同,它是建立在严格的数学概念基础上的;关系模型的概念单一,无论实体或实体之间的联系都用关系表示;存取路径对用户透明;关系必须是规范化的关系。
(10)C【解析】数据库逻辑设计的主要工作是将E―R图转换成指定的RDBMS中的关系模式。
(11)B【解析】在关系数据库系统中,数据库中的数据存储在二维表中,而表由记录构成,每个记录都具有相同的结构,即每个记录所包含的属性类型相同,而取值不同,因此可以肯定数据库中的记录之间存在联系。数据库中的数据项,也就是二维表的字段,而在数据库的表中,通常会设定某个字段或某些字段为键,通过这些键就可以确定其他字段的值,即数据库中的数据项之间也存在一定的关系,因此在关系型数据库系统中,数据库的数据项之间和记录之问都存在联系,正确答案应该是选项B。
(12)D【解析】创建数组的命令格式有两种:
DIMENSION<数组名>(<下标上限1>[,<下标上限2])[...]
DECLARE<数组名>(<下标上限1>[,<下标上限2])[...]
两种格式的功能完全相同。数组创建后,系统自动给每个数组元素赋以逻辑假(.F.)值。
(13)D【解析】在用双等号运算符比较两个字符串时,只有当两个字符串完全相同(含空格及各字符的位置、大小写),运算结果才为逻辑真。DTOC()函数作用是将日期型数据或日期时间型数据的日期部分转成字符串,所以DTOC({^09/13/2012 08:O0:O0})的结果是“09/1 3/2012”。
(14)C【解析】所谓自由表就是那些不属于任何数据库的表,所有t:h FoxBase或早期版本的FoxPro创建的数据库文件是自由表。可以将自由表移人到数据库中,也可以将数据库中的表移出,让它成为自由表。数据库表与自由表的最大区别是两者字段名的最大字符个数不同,数据库表中字段名的最大字符数为l28,而自由表中字段名的最大字符数为10。
(15)D【解析】G0命令直接对记录进行定位,TOP是表头,不使用索引时,即记录号为l的记录,使用索引时,为索引项排在最前面的索引对应的记录。BOTTOM是表尾,当不使用索引时是记录号最大的那条记录,使用索引时是索引项排在最后面的索引项对应的记录。GOT0命令用于直接定位到第几条记录。
(16)C【解析】与表名相同的结构索引在表打开时都能够自动打开,但是对于非结构索引,必须在使用之前打开索引文件。
单独的.idx索引是一种非结构单索引;采用非默认名的.cdx索引,也是非结构复合索引;与表名同名的.cdx索引,是结构复合索引。
结构复合索引具有如下特性:在打开表时自动打开;同一索引文件中能包含多个索引方案,或索引关键字;在添加、更改或删除记录时自动维护索引。
(17)D【解析】“级联”代表用新的连结字段值自动修改子表中的相关所有记录。“限制”代表若子表中有相关的记录,则禁止修改父表中的连结字段值。“忽略”代表若不做完整性检查即删除父表的记录时与子表无关。
(18)C【解析】使用窗口命令选择工作区格式为:sE. LECT<工作区>|<别名>。
<工作区号>的取值范围为0~32767。如果取值为0,则选择尚未使用的、编号最小的一个工作区。
<别名>是指打开表的别名,用来指定包含打开表的工作区。别名有3种使用方法:
使用系统默认的别名A―J表示前10个工作区;
使用用户定义的别名,定义格式为:USE表名ALIAS别名;
用户未定义别名时,直接使用表名作为别名。
另外,要为表指定打开的工作区,语法为:USE<表名> IN<工作区号>。此时并不改变当前区的位置。
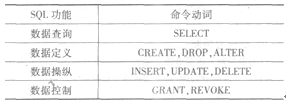
(19)B【解析】本题考查的SQL语言中各种语句所完成的功能,下表给出了SQL中常见的一些命令的功能。
(20)D【解析】本题所要求的是检索计算机系的学生,所以要有Where条件:院系=’计算机系’;另外检索结果只要学号和姓名,所以SELECT学号,姓名。因此本题答案是D。
相关推荐:
| 北京 | 天津 | 上海 | 江苏 | 山东 |
| 安徽 | 浙江 | 江西 | 福建 | 深圳 |
| 广东 | 河北 | 湖南 | 广西 | 河南 |
| 海南 | 湖北 | 四川 | 重庆 | 云南 |
| 贵州 | 西藏 | 新疆 | 陕西 | 山西 |
| 宁夏 | 甘肃 | 青海 | 辽宁 | 吉林 |
| 黑龙江 | 内蒙古 |